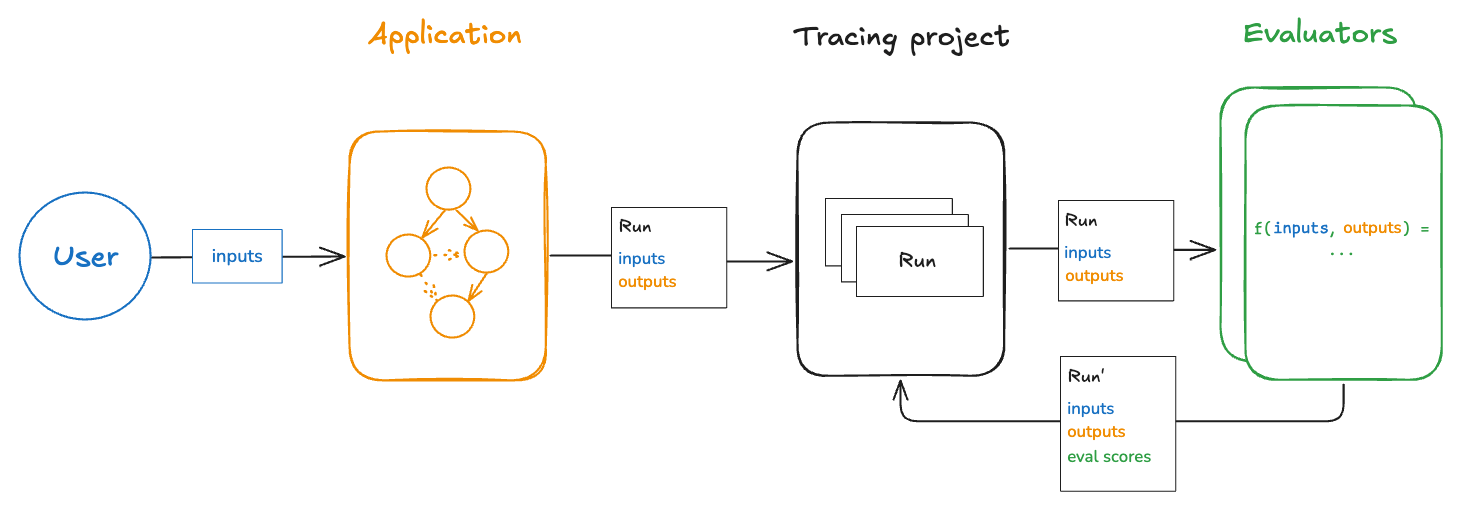
Offline evaluation types
Offline evaluation tests applications on curated datasets before deployment. By running evaluations on examples with reference outputs, teams can compare versions, validate functionality, and build confidence before exposing changes to users. Run offline evaluations client-side using the LangSmith SDK (Python and TypeScript) or server-side via the Prompt Playground or automations.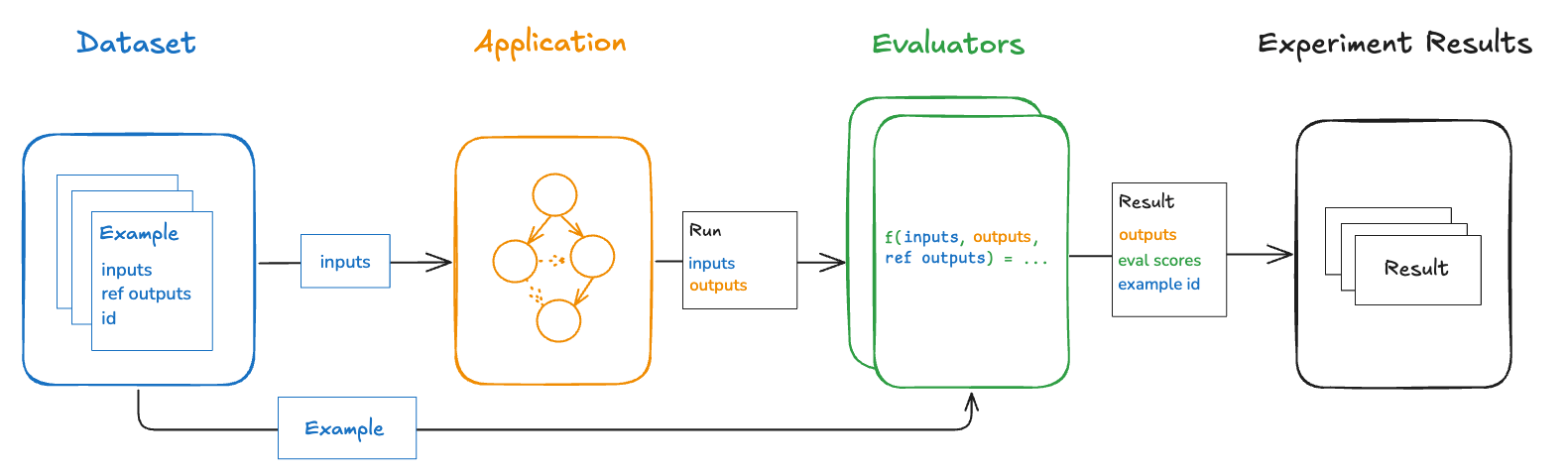
Benchmarking
Benchmarking compares multiple application versions on a curated dataset to identify the best performer. This process involves creating a dataset of representative inputs, defining performance metrics, and testing each version. Benchmarking requires dataset curation with gold-standard reference outputs and well-designed comparison metrics. Examples:- RAG Q&A bot: Dataset of questions and reference answers, with an LLM-as-judge evaluator checking semantic equivalence between actual and reference answers.
- ReACT agent: Dataset of user requests and reference tool calls, with a heuristic evaluator verifying all expected tool calls were made.
Unit tests
Unit tests verify the correctness of individual system components. In LLM contexts, unit tests are often rule-based assertions on inputs or outputs (e.g., verifying LLM-generated code compiles, JSON loads successfully) that validate basic functionality. Unit tests typically expect consistent passing results, making them suitable for CI pipelines. When running in CI, configure caching to minimize LLM API calls and associated costs.Regression tests
Regression tests measure performance consistency across application versions over time. They ensure new versions do not degrade performance on cases the current version handles correctly, and ideally demonstrate improvements over the baseline. These tests typically run when making updates expected to affect user experience (e.g., model or architecture changes). LangSmith’s comparison view highlights regressions (red) and improvements (green) relative to the baseline, enabling quick identification of changes.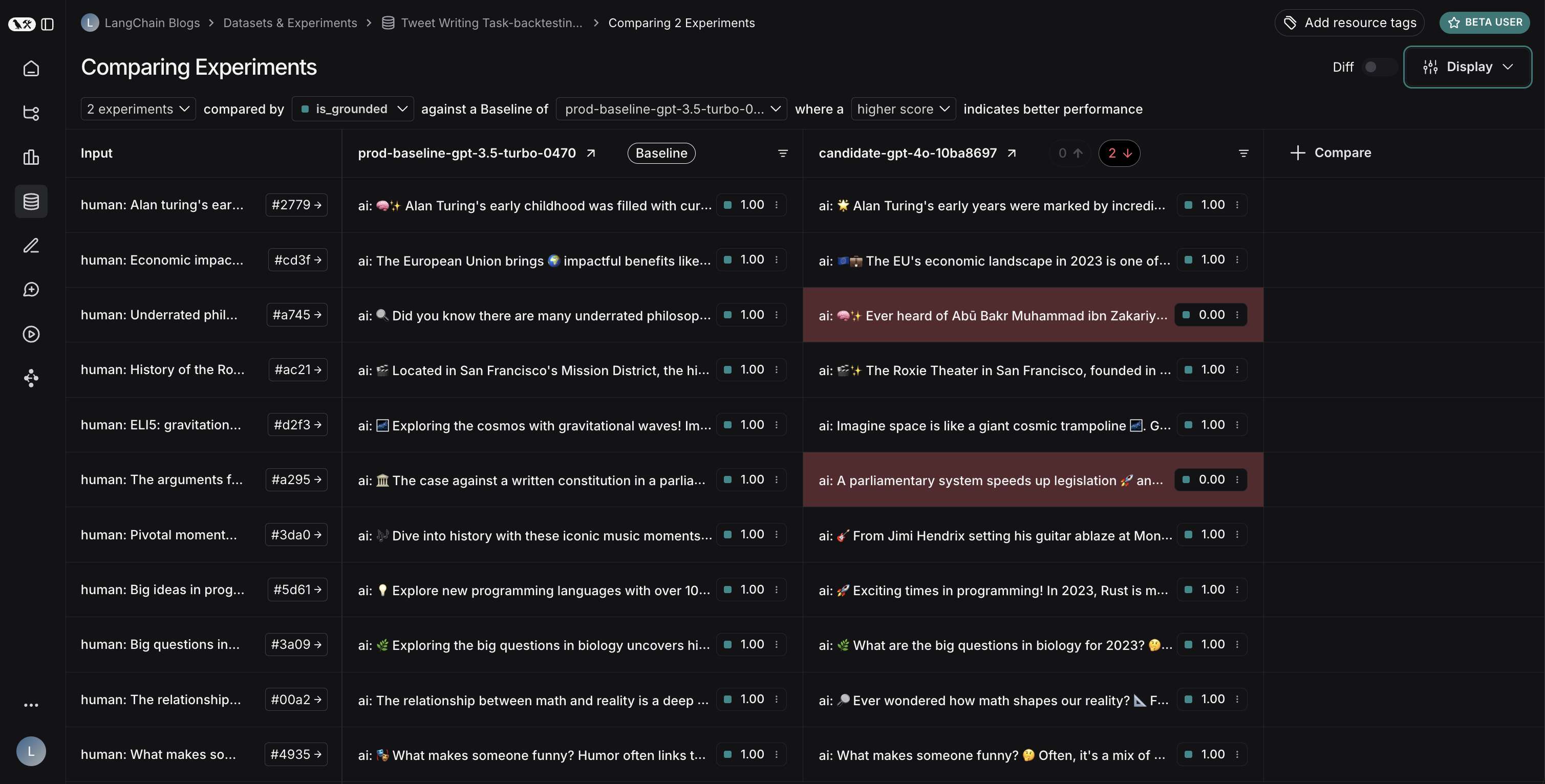
Backtesting
Backtesting evaluates new application versions against historical production data. Production logs are converted into a dataset, then newer versions process these examples to assess performance on past, realistic user inputs. This approach is commonly used for evaluating new model releases. For example, when a new model becomes available, test it on the most recent production runs and compare results to actual production outcomes.Pairwise evaluation
Pairwise evaluation compares outputs from two versions by determining relative quality rather than assigning absolute scores. For some tasks, determining “version A is better than B” is easier than scoring each version independently. This approach proves particularly useful for LLM-as-judge evaluations on subjective tasks. For example, in summarization, determining “Which summary is clearer and more concise?” is often simpler than assigning numeric clarity scores. Learn how run pairwise evaluations.Online evaluation types
Online evaluation assesses production application outputs in near real-time. Without reference outputs, these evaluations focus on detecting issues, monitoring quality trends, and identifying edge cases that inform future offline testing. Online evaluators typically run server-side. LangSmith provides built-in LLM-as-judge evaluators for configuration, and supports custom code evaluators that run within LangSmith.